It is becoming increasingly popular to consider throwing destructors a bad practice. Some people may even threaten you that they will make the next C++ standard require no-throw semantic on all destructors. Unfortunately, those people don't propose any reasonable alternative except, perhaps, not to use exceptions or not to use destructors. In this document I present my understanding of the problem and why, in my opinion, there is nothing wrong with throwing destructors.
If we can't throw from the destructor then what should we do in case of a failure? One of the following approaches is usually suggested.
Abort. If you encounter any failure during destruction then just abort the application:
T::~T () throw ()
{
try
{
// Code that could throw.
// ...
}
catch (...)
{
abort ();
}
}
Ignore. In other words, write you code like this:
T::~T () throw ()
{
try
{
// Code that could throw
// ...
}
catch (...)
{
// Maybe do some logging.
// ...
}
}
Pre-destroy. Provide a pre-destroy member function which can throw. If client code desires to handle destruction failures then it should call the pre-destroy function explicitly. The following code illustrates this idea:
void T::pre_destroy () throw (Failure)
{
// ...
}
T::~T () throw ()
{
try
{
pre_destroy ()
}
catch (...)
{
// Maybe do some logging.
// ...
}
}
I will start from the pre-destroy member function. Besides that it is aesthetically ugly, I managed to identify the following technical issues:
pre_destroy already does the job, e.g.:
void RefCountingObject::remove_ref ()
{
if (--count == 0)
{
pre_destroy ();
operator delete (*this);
}
}
for (;;)
{
std::auto_ptr<T> t (new T);
if (cond1)
{
t->pre_destroy (); // Defeats the purpose of RAII.
break;
}
else
{
break; // Degenerates to the Ignore case.
}
}
Now let us consider the Ignore case. When you absorb a failure inside the destructor you don't have much to choose from:
Even though Abort might be an overkill in some cases, it is the most ethical solution from all that were proposed. Note, however, that it doesn't play well with RAII either. I call this effect abort escalation. Consider the following sample code:
struct Mutex
{
~Mutex () throw ()
{
try
{
// Destroy underlying OS primitive.
}
catch (...)
{
abort ();
}
}
void lock (); // can throw
void unlock (); // can throw
// ...
};
struct AutoLock
{
AutoLock (Mutex& m)
: m_ (m)
{
m_.lock ();
}
~AutoLock () throw ()
{
try
{
m_.unlock ();
}
catch (...)
{
abort ();
}
}
//...
};
In this example, by using AutoLock we escalate abort-if-failed
semantics on Mutex::unlock member function.
According to clause 3.8 paragraph 1 of the C++ Standard,
The lifetime of an object of type T ends when: -- if T is a class type with a nontrivial destructor (12.4), the destructor call starts, or -- the storage which the object occupies is reused or released.
Also clause 12.4 paragraph 14 states,
Once a destructor is invoked for an object, the object no longer exists; the behavior is undefined if the destructor is invoked for an object whose lifetime has ended (3.8).
So no matter whether the destructor for the object completed normally or terminated with an exception, the lifetime of the objects has ended and the object no longer exists. Now let us concentrate on the case when the destructor terminates with an exception. According to clause 15.2 paragraph 2,
An object that is partially constructed or partially destroyed will have destructors executed for all of its fully constructed sub-objects, that is, for sub-objects for which the constructor has completed execution and the destructor has not yet begun execution.
The following small program illustrates the partially destroyed case.
#include <iostream>
using std::cerr;
using std::endl;
struct A
{
~A ()
{
cerr << "A::~A" << endl;
// (1)
}
};
struct B
{
~B ()
{
cerr << "B::~B" << endl;
// (2)
}
};
struct C : A
{
~C ()
{
cerr << "C::~C" << endl;
// (3)
}
B b;
};
int main ()
{
try
{
C c;
}
catch (...){}
}
According to the Standard, sub-objects are destroyed in the reverse order of their construction and the output of the program above should look like this:
C::~C B::~B A::~A
Furthermore, clause 15.2 paragraph 2 guarantees that if we throw an exception in place of (3), the process of destroying sub-objects is not abandoned and the output will be the same. Likewise, it will be the same if we throw an exception in place of (1) or (2).
Thus, the Standard takes an extra measure to ensure that all sub-objects are going to be destroyed even in case an exception has been thrown by one of the participating destructors. It doesn't mean, however, that it's impossible to write a destructor that will leak a resource in case of an exception:
class IO_Buffer
{
char* buf_;
// ...
void flush (); // can throw
public:
~IO_Buffer ()
{
flush ();
delete[] buf_;
}
};
One of the possible solutions could look like this:
IO_Buffer::~IO_Buffer ()
{
try
{
flush ();
}
catch (UnableToFlush const& e)
{
// Provide unflushed data with the exception.
//
throw UnableToFlushBuf (e, buf_);
}
delete[] buf_;
}
But what if we had more than one place in the destructor that could throw an exception? For instance, consider this example:
class File
{
char* buf_;
// ...
void flush (); // can throw
void close (); // can throw
public:
~File ()
{
try
{
flush ();
}
catch (UnableToFlush const& e)
{
try
{
close ();
}
catch (...)
{
// what to do here?
}
throw UnableToFlushBuf (e, buf_);
}
delete[] buf_;
close ();
}
};
In an ordinary function we would have stopped immediately if flush
had failed and let a caller decide what to do next. But remember, no matter
how the destructor terminates, the object does not exist anymore. Thus, in the case
of the destructor, we are forced to complete the job no matter what. The next
section is going to give an answer to the "what to do here?" question.
Before dwelling into details of C++ exception handling, it might be useful to review some general concepts of fault-tolerant computing. After all, C++ exception handling mechanism was designed to deal with failures and a generalized perspective may help to better understand the situation at hand.
A system can be viewed as a module which can be composed of other modules. Each module has a specified (or expected) behavior and an observed behavior. A failure occurs when the observed behavior does not match the specified behavior. A failure occurs because of an error in the module. The cause of the error is a fault.
For example, a buggy application (fault) allocated all available memory (error). When another application tries to allocate some memory from the free store, operation fails (failure).
The time between the occurrence of the error and the resulting failure is called the error latency. A module is called failfast if it stops operating when it detects a failure and it has small error latency. Failfast behavior is critical because a single latent error can lead to a cascade of faults if a latent faulty module is used by other modules.
Module reliability can be improved by designing it to tolerate certain faults. Faulty behavior is then dichotomized into expected faults (tolerated by the design) and unexpected faults (not tolerated by the design). Unexpected faults can be divided into two groups:
Now let us try to position C++ exception handling mechanism in the model
established above. Suppose we have a failfast module
A:
struct A
{
class Failed {};
void perform () throw (Failed)
{
throw Failed (); // (1)
}
};
If module A can't perform its job, it immediately stops operating and reports
the failure by throwing an exception. Suppose we have another module, B,
which is built upon module A:
struct B
{
void perform ()
{
try
{
// (2)
A a;
a.perform ();
}
catch (A::Failed const&)
{
// (3)
}
}
};
By putting try and later catch (A::Failed const&)
inside B::perform we are indicating that module B is
going to somehow handle the potential failure of module A.
Now let us consider what happens when A::perform throws
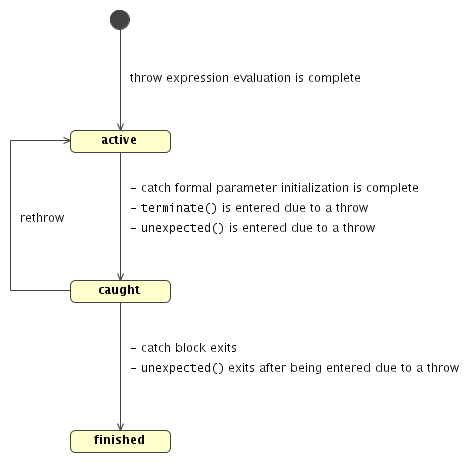
an exception at line (1). The picture below shows the exception state diagram
as specified by the C++ Standard.
After constructing a temporary of type A::Failed at line (1), the
exception becomes active. When an exception is active, the language runtime
is performing control transfer from the throw statement to the first matching
handler. In our case it would be from line (1) to line (3). It is worth noting
that, once an exception became active, all the actions performed by the language runtime during
control transfer are part of the recovery. One of those actions, called stack unwinding
, consists of destroying all automatic objects constructed on the path from a try
block to a throw expression (from line (2) to line (1) in our case). But what happens if
a destructor, called by the language runtime during stack unwinding, exits with an exception?
And what would it mean?
The answer to the first question is simple: std::terminate is called
which in turn terminates the program. The second question is more subtle and that's where
we will try to apply our model of fault-tolerant computing. Stack unwinding is a
part of the recovery process. An exception from one of the destructors would indicate
a second failure in the recovery period. If that happens, the runtime terminates the process.
All this indicates that C++ exception handling mechanism is 1-fault tolerant
and exhibits failfast behavior in case of Dense faults by terminating
the process. Or, putting it more precise, in the presence of throwing destructors, C++ exception
handling mechanism is 1-fault tolerant and exhibits failfast behavior
in case of Dense faults.
Now, with the light of new understanding, let us go back to our unfinished example from the previous section. Since we decided to allow throwing from destructors (more on that later), C++ exception handling mechanism becomes 1-fault tolerant. In other words, your application is built upon a module (C++ exception handling) which is 1-fault tolerant and will terminate application in case of a dense fault. This effectively makes the whole application not more than 1-fault tolerant. Now to our destructor. The question was what to do if there is a second (dense) failure? Since our application is already not more than 1-fault tolerant, there is not much sense in making one of its components more than 1-fault tolerant. Thus, the answer to the question would simply be call std::terminate.
You are probably thinking that, since throwing destructors do not allow you to write more than 1-fault tolerant applications, it makes perfect sense to ban such destructors. There are two considerations to this thought.
First, there is no alternative to throwing an exception from a
destructor (except not using destructors and/or exceptions all together,
of course). Second consideration is of a more philosophical nature. Suppose
you are writing an n-fault tolerant application running in a
single process. What n would you target? The only practical
values are 0, 1 and infinity. It
is generally understood that infinity is not feasible in a
single-process application; 0 and 1 are possible
with throwing destructors.
There are two cases to consider: destruction of a dynamically allocated object
and destruction of a dynamically allocated array of objects. In the first case, the
Standard does not specify what happens to the memory if the destructor exits with
an exception. For example, in the following code, the Standard doesn't guarantee
that dynamically allocated memory, used for the instance of type S
will be released:
struct S
{
~S ()
{
throw 0;
}
};
void f ()
{
try
{
delete new S;
}
catch (...){}
}
While the same holds true for dynamically allocated arrays, they have an additional problem. The Standard doesn't require calling destructors for the rest of the objects if for one of them the destructor terminated with an exception. By analogy with sub-objects, it would be logical to expect such behavior. The following code shows how it could work:
template <typename T>
void destroy (T* p)
{
p->~T ();
}
template <typename I>
void destroy (I* begin, I* end)
{
I* i (end);
try
{
// Destroy in last-first order which usually means
// reverse order with regard to construction.
//
for (; i != begin; --i) destroy (&*(begin - 1));
}
catch (...) // destructor failure
{
try
{
// Try to finish the job.
//
for (--i; i != begin; --i) destroy (&*(begin - 1));
}
catch (...)
{
// Second failure while recovering. Resorting to
// the less subtle recovery mechanism.
//
std::terminate ();
}
throw;
}
}
See also The C++ Standard issue 353 for some details about how it could be addressed in the future.
The original plan for this section was to show how to write generic containers in the face of throwing destructors. But later I realized that, mainly due to its volume and complexity, this subject deserves separate treatment. Thus, it will appear as a separate document.
Copyright © 2003, 2004 Boris Kolpackov. See license for conditions.
Last updated on March 1 2004